受人所托,搞一搞实时目标检测,于是了解到了YOLOv8
运行环境
- Python>=3.8
- PyTorch>=1.8
推荐使用anaconda创建虚拟环境,并安装依赖包
1
2
|
# Install all packages together using conda
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
|
其实项目库里有requirements.txt也可以
1
|
pip install -r requirements.txt
|
运行
命令行
进入你的文件夹中,激活用anaconda创建的虚拟环境,我这里的环境名字叫yolov8,然后执行
1
|
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
|
其中source地址可换成本地图片地址,model也可更换,这里的yolov8n.pt是官方给出的最快速最轻量的模型,但相应的准确率就不是最高了。
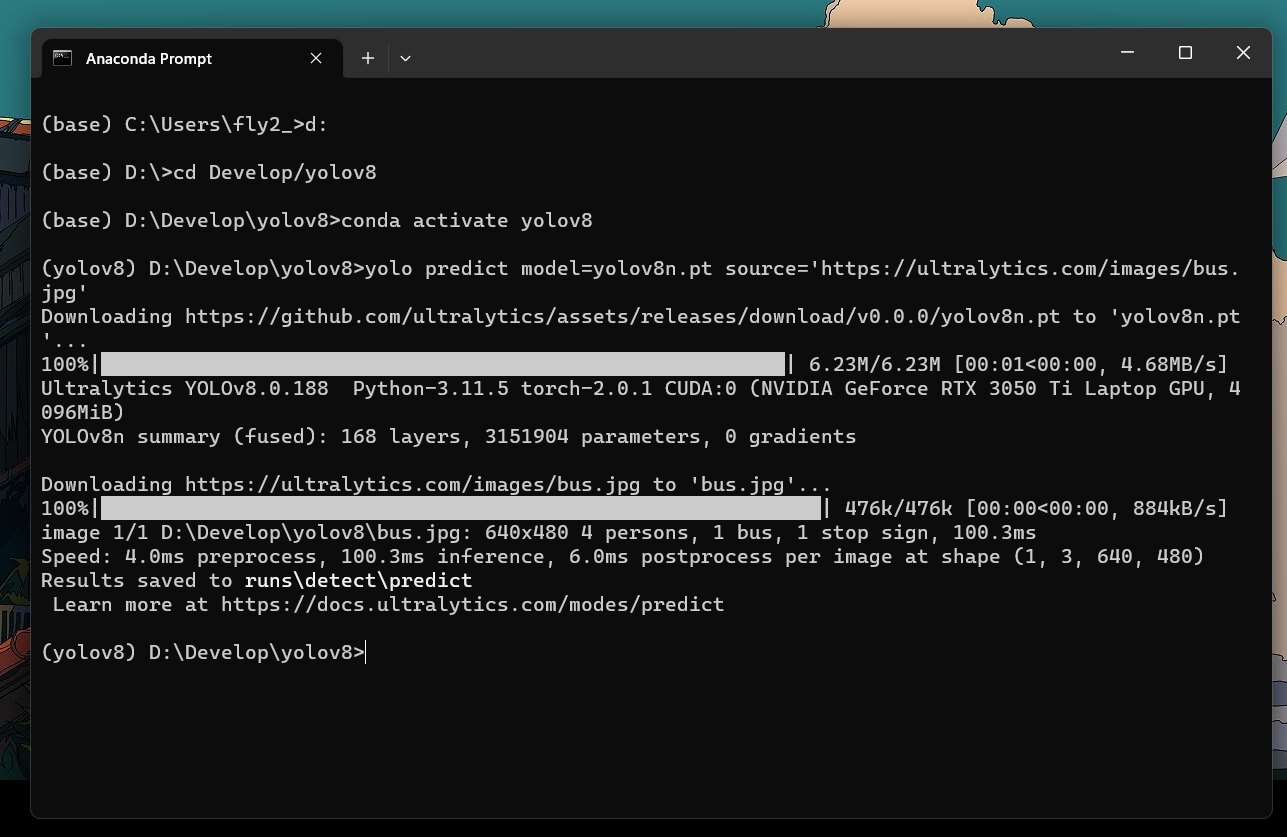
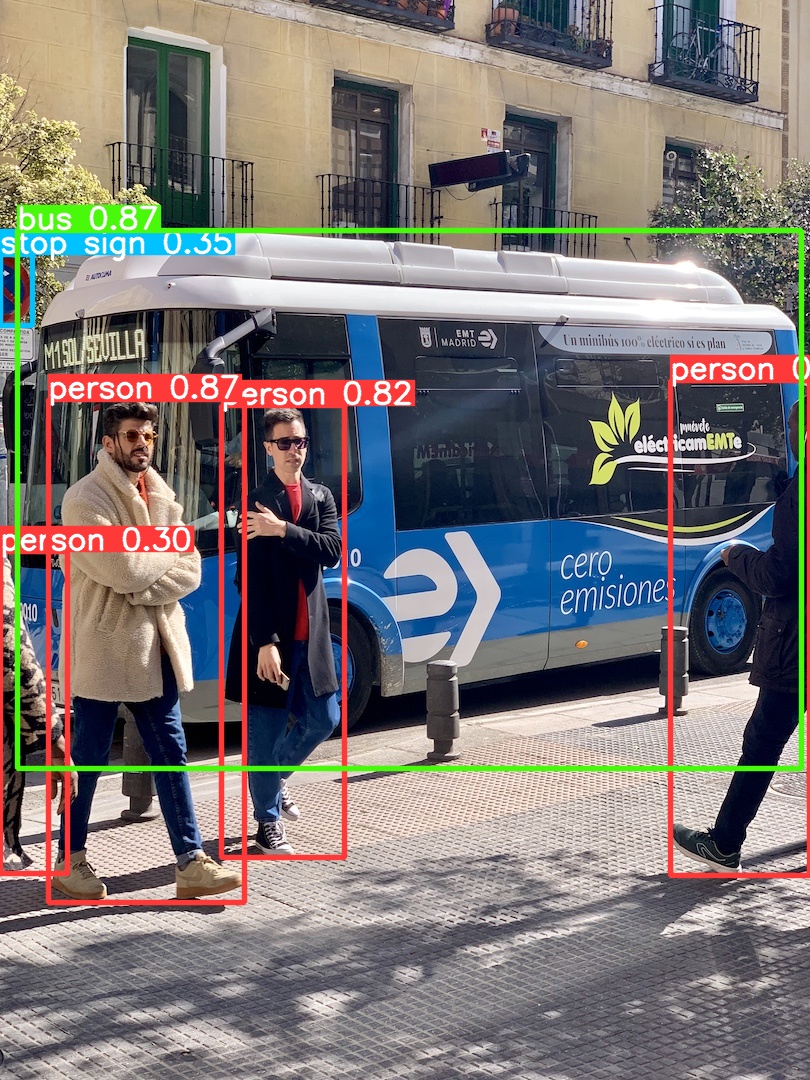
结果保存在\runs\detect\predict下
python代码
1
2
3
4
5
6
7
8
9
10
11
|
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.yaml") # 从头开始构建新模型
model = YOLO("yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
model.train(data="coco128.yaml", epochs=3) # 训练模型
metrics = model.val() # 在验证集上评估模型性能
results = model("https://ultralytics.com/images/bus.jpg") # 对图像进行预测
success = model.export(format="onnx") # 将模型导出为 ONNX 格式
|
以上就是最为基础的用法,反正是挺简单的。
实时检测
但朋友的要求是从摄像头获取输入,并实时检测,于是配合OpenCV有了以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import cv2
from ultralytics import YOLO
import numpy as np
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
results = model.track(frame, persist=True)
frame_ = results[0].plot()
cv2.imshow('YOLO',frame_)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
|
(自己测试,我就不放视频了😉)
(不想写了,就这样吧)
